接口幂等性问题
接口调用出现的问题
在分布式架构的系统中,通常是多个微服务之间互相调用,而服务调用服务无非就是 RPC 或 Restful 进行通信,既然是通信,那么就存在服务器处理完毕返回结果的途中挂掉,这也是分布式系统因网络不可达出现的问题。这个时候用户端很久没有得到服务端的响应,那么就会多次点击按钮,这样请求多次,那么处理数据的结果是否要保持一致呢?答案是肯定的!尤其是在一些订单与支付的场景。
什么是接口幂等性?
接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额返发现多扣钱了,流水记录也变成了两条,这就没有保证接口的幂等性。
什么情况下需要保持接口的幂等性?
我们对处理数据无非就是增删改查四个操作?那么那些操作需要保持接口的幂等性?==> insert 与 update
- 查询操作 ==> 查询一次或者多次对于结果的影响是不会有改变的,所以 select 是天然的幂等性操作
- 删除操作 ==> 删除一次与删除多次都是将数据删除(但是注意返回的结果是不一样的,成功 1 失败 0,在不考虑结果的情况下,删除操作也是幂等性操作)
- 更新操作 ==> 修改操作在大多情况下结果都是一样的,除非是增量修改,那么就是要保持幂等性的。例如:
- 将表中的某条记录的某个字段设置为 1 ==> 这个操作不管执行多少次都是幂等的
- 将表中的某条记录的某个字段增加 1 ==> 这个操作是不保证幂等性的
- 新增操作 ==> 新增操作肯定是会出现幂等性问题的,例如上面的支付问题。、
那么如何才能保持接口的幂等性?
增加数据之前先查询
通常情况下,在保存数据的接口中,我们为了防止产生重复数据,一般会在insert前,先根据name或code字段select一下数据。如果该数据已存在,则执行update操作,如果不存在,才执行insert操作。

==该方案并不适用于并发场景,在并发场景中,要配合其他的方案一起使用,否则还是会造成重复的数据。==
加悲观锁
在支付场景中,用户 A 的账号余额有 150 元,想转出 100 元,正常情况下用户 A 的余额只剩 50 元。一般情况下,sql 是这样的:
1 | update user amount = amount-100 where id=123; |
如果出现多次相同的请求,可能会导致用户 A 的余额变成负数。这种情况,用户 A 来可能要哭了。与此同时,系统开发人员可能也要哭了,因为这是很严重的系统 bug。
为了解决这个问题,可以加悲观锁,将用户 A 的那行数据锁住,在同一时刻只允许一个请求获得锁,更新数据,其他的请求则等待。
通常情况下通过如下 sql 锁住单行数据:
1 | select * from user id=123 for update; |
具体的流程如下:

具体步骤:
- 多个请求同时根据 id 查询用户信息
- 判断余额是否不足 100,如果余额不足,则直接返回余额不足
- 如果余额充足,则通过 for update 再次查询用户信息,并且尝试获取锁
- 只有第一个请求能获取到行锁,其余没有获取锁的请求,则等待下一次获取锁的机会
- 第一个请求获取到锁之后,判断余额是否不足 100,如果余额足够,则进行 update 操作
- 如果余额不足,说明是重复请求,则直接返回成功
需要特别注意的是:如果使用的是 mysql 数据库,存储引擎必须用 innodb,因为它才支持事务。此外,这里 id 字段一定要是主键或者唯一索引,不然会锁住整张表。
悲观锁需要在同一个事务操作过程中锁住一行数据,如果事务耗时比较长,会造成大量的请求等待,影响接口性能。
此外,每次请求接口很难保证都有相同的返回值,所以不适合幂等性设计场景,但是在防重场景中是可以的使用的。
在这里顺便说一下,防重设计和幂等设计,其实是有区别的。 防重设计主要为了避免产生重复数据,对接口返回没有太多要求。 而幂等设计除了避免产生重复数据之外,还要求每次请求都返回一样的结果。
加乐观锁
既然悲观锁有性能问题,为了提升接口性能,我们可以使用乐观锁。需要在表中增加一个timestamp或者version字段,这里以version字段为例。
在更新数据之前先查询一下数据:
1 | select id,amount,version from user id=123; |
如果数据存在,假设查到的version等于1,再使用id和version字段作为查询条件更新数据:
1 | update user set amount=amount+100,version=version+1where id=123 and version=1; |
更新数据的同时version+1,然后判断本次update操作的影响行数,如果大于 0,则说明本次更新成功,如果等于 0,则说明本次更新没有让数据变更。
由于第一次请求version等于1是可以成功的,操作成功后version变成2了。这时如果并发的请求过来,再执行相同的 sql:
1 | update user set amount=amount+100,version=version+1where id=123 and version=1; |
该update操作不会真正更新数据,最终 sql 的执行结果影响行数是0,因为version已经变成2了,where中的version=1肯定无法满足条件。但为了保证接口幂等性,接口可以直接返回成功,因为version值已经修改了,那么前面必定已经成功过一次,后面都是重复的请求。
具体的流程如下:

具体步骤:
- 先根据 id 查询用户信息,包含 version 字段
- 根据 id 和 version 字段值作为 where 条件的参数,更新用户信息,同时 version+1
- 判断操作影响行数,如果影响 1 行,则说明是一次请求,可以做其他数据操作
- 如果影响 0 行,说明是重复请求,则直接返回成功
加唯一索引
绝大数情况下,为了防止重复数据的产生,我们都会在表中加唯一索引,这是一个非常简单,并且有效的方案。
1 | alter table `order` add UNIQUE KEY `un_code` (`code`); |
加了唯一索引之后,第一次请求数据可以插入成功。但后面的相同请求,插入数据时会报Duplicate entry '002' for key 'order.un_code异常,表示唯一索引有冲突。
虽说抛异常对数据来说没有影响,不会造成错误数据。但是为了保证接口幂等性,我们需要对该异常进行捕获,然后返回成功。
如果是java程序需要捕获:DuplicateKeyException异常,如果使用了spring框架还需要捕获:MySQLIntegrityConstraintViolationException异常。
具体流程如下:

具体步骤:
- 用户通过浏览器发起请求,服务端收集数据
- 将该数据插入 mysql
- 判断是否执行成功,如果成功,则操作其他数据(可能还有其他的业务逻辑)
- 如果执行失败,捕获唯一索引冲突异常,直接返回成功
根据状态判断
很多时候业务表是有状态的,比如订单表中有:1-下单、2-已支付、3-完成、4-撤销等状态。如果这些状态的值是有规律的,按照业务节点正好是从小到大,我们就能通过它来保证接口的幂等性。
假如 id=123 的订单状态是已支付,现在要变成完成状态:
1 | update `order` set status=3 where id=123 and status=2; |
第一次请求时,该订单的状态是已支付,值是2,所以该update语句可以正常更新数据,sql 执行结果的影响行数是1,订单状态变成了3。
后面有相同的请求过来,再执行相同的 sql 时,由于订单状态变成了3,再用status=2作为条件,无法查询出需要更新的数据,所以最终 sql 执行结果的影响行数是0,即不会真正的更新数据。但为了保证接口幂等性,影响行数是0时,接口也可以直接返回成功。
具体的流程如下:

具体步骤:
- 用户通过浏览器发起请求,服务端收集数据
- 根据 id 和当前状态作为条件,更新成下一个状态
- 判断操作影响行数,如果影响了 1 行,说明当前操作成功,可以进行其他数据操作
- 如果影响了 0 行,说明是重复请求,直接返回成功
主要特别注意的是,该方案仅限于要更新的表有状态字段,并且刚好要更新状态字段的这种特殊情况,并非所有场景都适用。
加分布式锁
其实前面介绍过的加唯一索引或者加防重表,本质是使用了数据库的分布式锁,也属于分布式锁的一种。但由于数据库分布式锁的性能不太好,我们可以改用:redis或zookeeper。本文主要介绍redis的分布式锁:
目前主要有三种方式实现 redis 的分布式锁:
- setNx 命令
- set 命令
- Redission 框架
具体流程如下:

具体步骤:
- 用户通过浏览器发起请求,服务端会收集数据,并且生成订单号 code 作为唯一业务字段
- 使用 redis 的 set 命令,将该订单 code 设置到 redis 中,同时设置超时时间
- 判断是否设置成功,如果设置成功,说明是第一次请求,则进行数据操作
- 如果设置失败,说明是重复请求,则直接返回成功
需要特别注意的是:分布式锁一定要设置一个合理的过期时间,如果设置过短,无法有效的防止重复请求。如果设置过长,可能会浪费 redis 的存储空间,需要根据实际业务情况而定。
根据 token 判断
除了上述方案之外,还有最后一种使用token的方案。该方案跟之前的所有方案都有点不一样,需要两次请求才能完成一次业务操作。
- 第一次请求获取
token - 第二次请求带着这个
token,完成业务操作
具体的流程如下:
获取
token
做具体业务
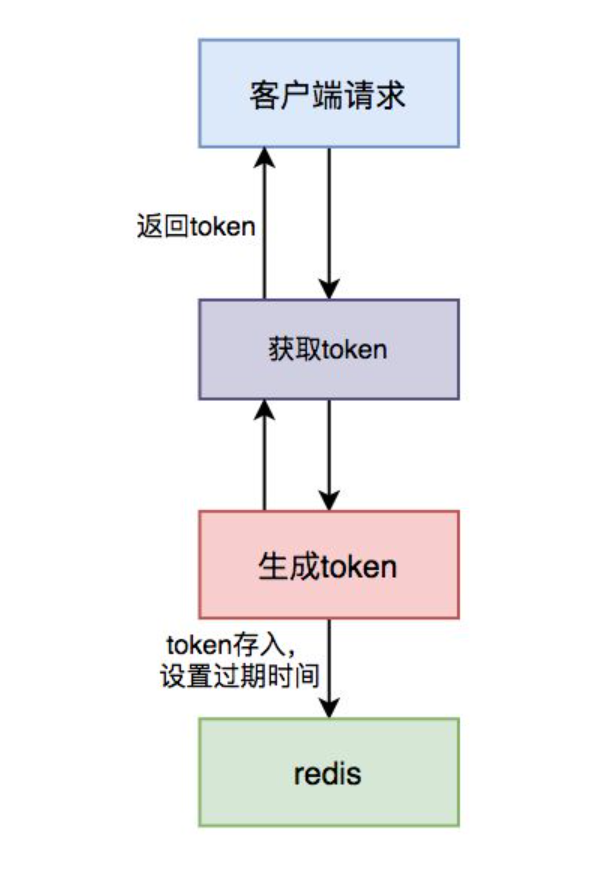

具体步骤:
- 用户访问页面时,浏览器自动发起获取 token 请求
- 服务端生成 token,保存到 redis 中,然后返回给浏览器
- 用户通过浏览器发起请求时,携带该 token
- 在 redis 中查询该 token 是否存在,如果不存在,说明是第一次请求,做则后续的数据操作
- 如果存在,说明是重复请求,则直接返回成功
- 在 redis 中 token 会在过期时间之后,被自动删除
需要特别注意的是:token 必须是全局唯一的。












